
This post is the second of a two part series about redirect chains. Part one talked about what redirect chains are and the implications they have for SEO. Part two shows you how to find them.
Finding and Identifying Redirect Chains
In order to find redirect chains, you’ll have to start with a group of URLs. There are four main methods I typically use to find them and I’ll walk you through that now. Please note, all four strategies will require the paid version of the Screaming Frog SEO Spider. A license costs ~$150 a year, but worth every penny.
Strategy One: Google Analytics
Go as far back in Google Analytics as you can and export as many landing pages as you can. Make sure you’re in the Acquisition > Channels > Organic Search report. Select “landing pages” as the primary dimension, make sure your date range is set as far back as possible and the number of rows is set to 5,000.
We want as many old URLs as possible and once you’ve done this, you can select ‘Export CSV’ and download a spreadsheet of landing page URLs.
Strategy Two: Exporting Backlinks
Strategy two aggregates URLs from backlink tools such as Moz’s Open Site Explorer, SEMrush, Ahrefs or others. I’m using Moz’s OSE because it’s a free tool that you can get access to just by creating an account.
Once you’ve logged in, enter the site in question into the search bar. Next, select ‘root domain’ under Target – this ensures we’re getting backlinks to the entire site. Leave Link Source as ‘Only External’ and set Link Type to ‘All Links.’
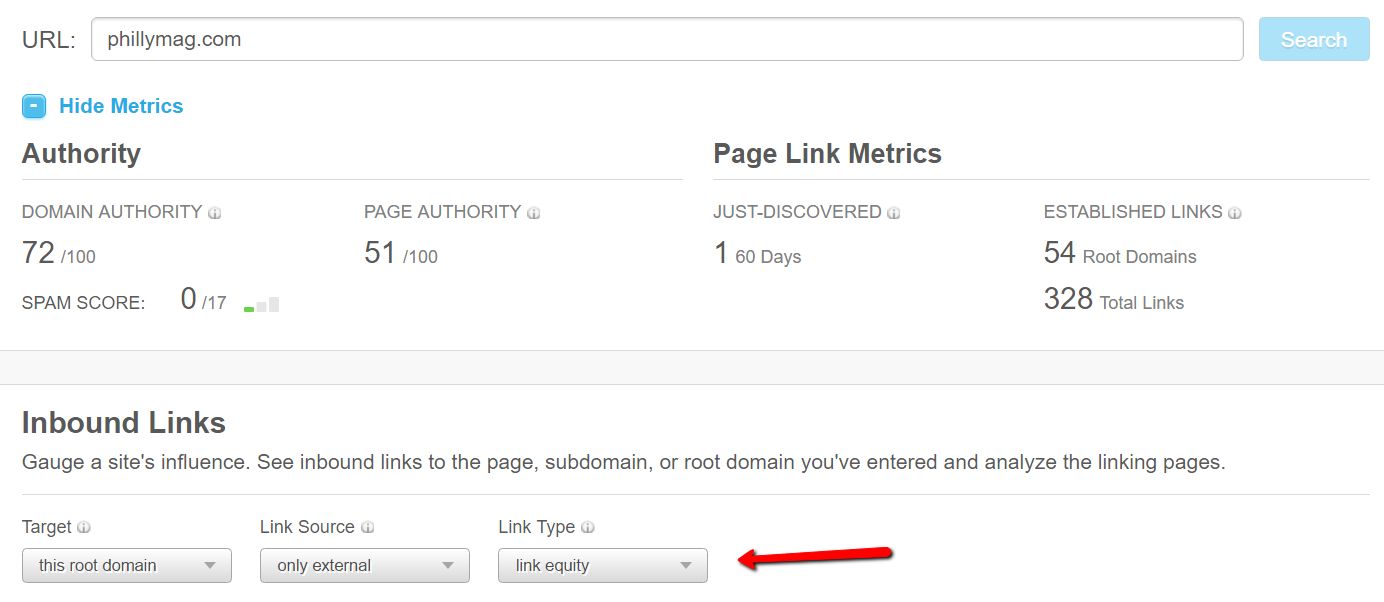
Also remember to ask yourself: was this site hosted on a different domain at some point? Make sure you export backlinks for that domain also.
Crawling Lists of URLs
Once you’ve exported URLs, you’ll need to crawl them in Screaming Frog’s list mode.
- Under Mode, select List
- Under Configuration > Spider > Advanced, check the “Always follow redirects” box.
- Under Configuration > robots.txt > Settings, check the “Ignore robots.txt” box
Now you can crawl the list of URLs to look for redirects. After I explain strategies three and four, I’ll show you how to export the redirect chains.
Strategy Three: Crawling the Site
It’s entirely possible that there are redirect chains currently present on the site (these may initially present themselves as internal 301 redirects, which are not ideal anyway).
How to Crawl for Redirect Chains
First adjust your settings in Screaming Frog:
- Under Mode, select Spider
- Under Configuration > Spider > Advanced, check the “Always follow redirects” box.
- Under Configuration > robots.txt > Settings, check the “Ignore robots.txt” box.
Now grab the URL, enter it into Screaming Frog and start crawling.
Strategy Four: Crawling Old Versions of the Site
This is where we get advanced. Go to archive.org/web and enter your root domain.
Now select an older version of the site.
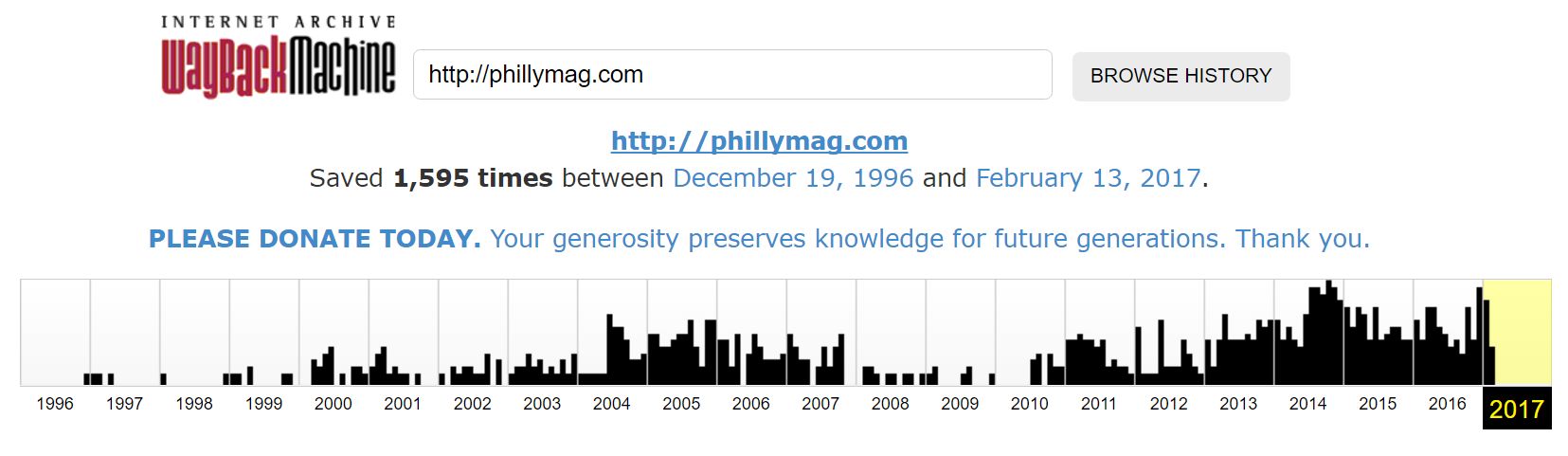
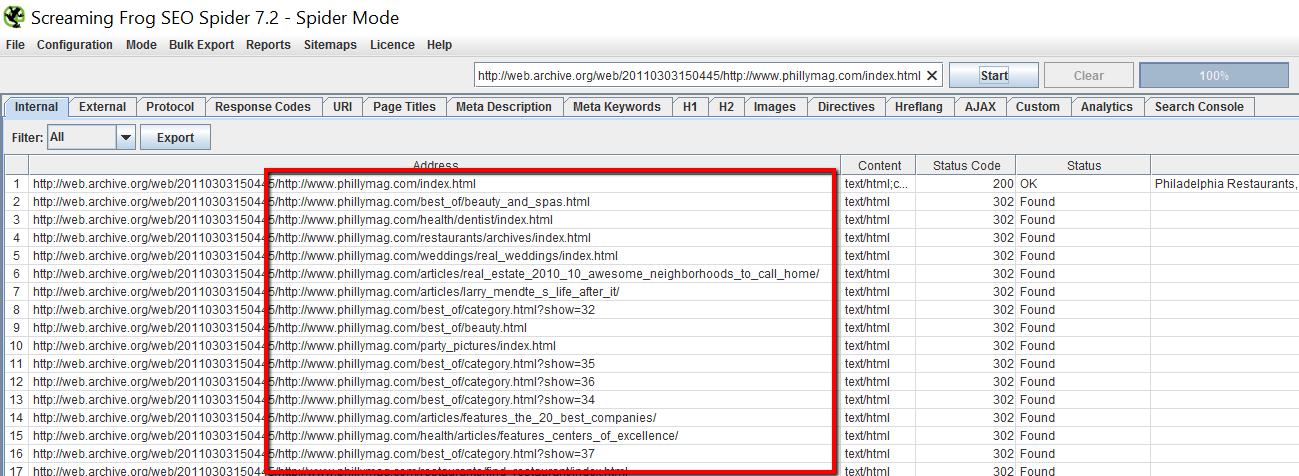
Then take that URL and crawl it with Screaming Frog, same as we did in Strategy Three.

You’ll see Screaming Frog will crawl a bunch of web.archive.org URLs, but the URLs you want are included at the end of that. You’ll need to export these, remove the web.archive.org part and then run them through Screaming Frog again in list mode.
Exporting Redirect Chains from Screaming Frog
Once all your crawls have finished, you can export the redirect chains from Screaming Frog.
- Go to Reports and select Redirect Chains.
- Save as a CSV.
In Excel, you can now perform some basic sorting and filtering to make the results easier to parse. First, I’ll sort for redirect loops, if there are any. Next, I’ll sort by number of redirects in order to prioritize. Thirdly, I’ll run some conditional formulas to highlight URLs returning status codes other than 200 or 301 (302, 404, 500, etc.)
The outcome of this analysis will present several actionable recommendations:
- Eliminate redirect loops if there are any.
- Eliminate redirect chains in favor of single redirects.
- Replace any 302 or 404 status codes with 301s.
If you have any questions, leave them in the comments, or tweet @BerkleyBikes and I’ll be happy to answer them.

I’m Facing a Problem about Redirect Chain’s I Don’t know what to do with that. Can U Help me About this Issue?
here a link for more information.
plz.
Hi Chris,
On one of our sites, we’ve chosen the non-www version as the preferred version in search console and implemented one redirect from http to https and then a second from www to non www.
I’m worried about taking the approach in the article and consolidating these redirects into one (i.e. directly from http://www to https://) as there are some inbound links to the https://www version which we presumably would lose link value for (as well as throwing 404s to users).
Have you got any suggestions on what to do in this situation?
Thanks in advance,
Darren
Hi Darren – That’s a valid concern. In that scenario, you’d want to set up another rule that redirects the https://www to https://. That way, you eliminate the redirect chain in the first scenario but don’t lose the link equity or provide a bad user experience as you mentioned in the second scenario. I recommend that all versions of a URL should redirect to the preferred version, else you run into the the problems you mentioned above.