Let’s talk about bounce rates. The reason we’re talking about them is because they’re largely misunderstood and less scrupulous (less informed?) marketers than myself routinely make claims about lowering bounce rate…as if that’s universally a positive thing. It may be. Or it might not matter. Read on and I’ll explain why.
What Is Bounce Rate?
Before we really get into it, let’s recap what bounce rate is. Bounce rate is the percentage of visitors who have one single Google Analytics hit during their site session, before leaving. Very often, it is incorrectly stated that bounce rate is the percentage of people who view one page before leaving, but that’s not necessarily true. A pageview is a type of hit, but not all hits are pageviews (I’ll explain why in a few paragraphs).
Bounce rate is one of the metrics in the Google Analytics default report (the first screen you see when you login). I absolutely revile this report. I know its intentions are good, but I’ve seen far too many reports recapping these numbers and nothing else (to be fair, there was a time when a less-worldly version of myself created said reports).
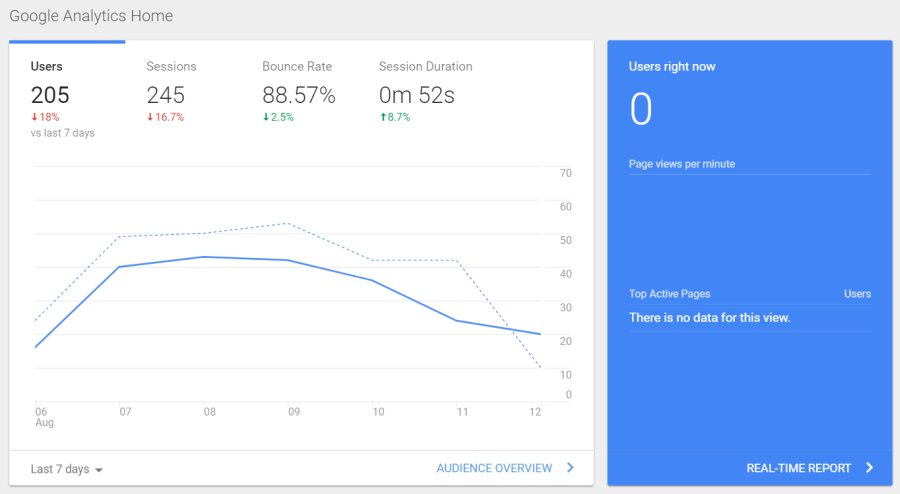
The default report is especially worthless because it looks at bounce rate across the entire site and that’s an utterly stupid way to use that metric. Different types of pages or marketing channels will have vastly different bounce rates and you shouldn’t roll them into one site-wide number.
The red/green colored text leads you to believe that a lower bounce rate is good and a higher bounce rate is bad, but consider this: What if someone lands on a location page where they get directions or a phone number? In that scenario, they might be considered a bounce, but in reality, they completed an action that takes them one step closer to being a customer.
Or, what if the page is lead-gen oriented, contains a form and gives visitors all the information they came for, without the need to click on another page? That may also be considered a bounce, but if the visitor converts into a lead, who cares?
What if the page has a baking recipe on it, and visitors spend 20+ minutes with the page open while they use that recipe, then close the browser when they’re done? Possibly still a bounce.
I could go on, but I won’t because I’ve made my point – there are plenty of scenarios where bounces are not something to be concerned about.
When Is Bounce Rate Bad?
If your site makes money from ad revenue, bounce rate could certainly be an issue. Most ad-based sites rely on multiple pageviews per session so they can cycle more ads and increase the likelihood one one of them is relevant and gets clicked. Ever wonder why “22 Photos of Cats in Boxes” takes 24 pages to finish reading? Ad revenue, that’s why.
Similarly, if you have a high bounce rate on gateway pages that are supposed to funnel traffic to other pages on the site, that could be an issue. Even then, it’s highly dependent on the site/design/business model/industry.
In other words, yes, a high bounce can be a problem, but should be evaluated on a case-by-case basis and with plenty of scrutiny. Looking at a site-wide bounce rate is a complete waste of time, and an exercise in futility.
Interaction vs. Non-Interaction Hits
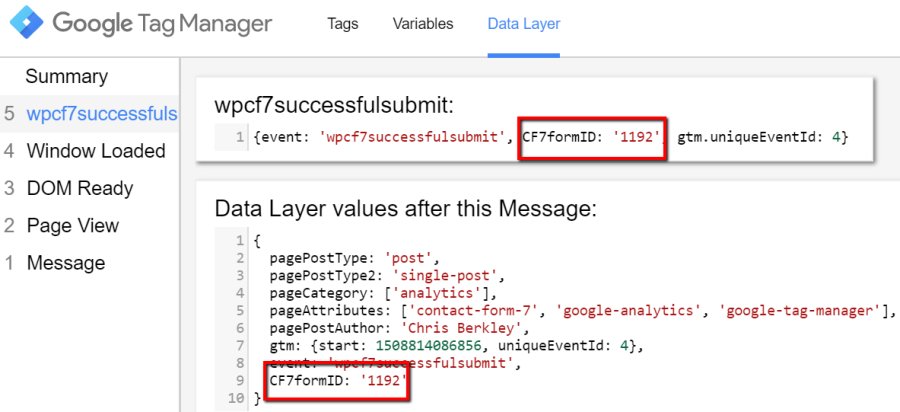
Earlier I said bounce rate is based on the number of hits and not pageviews. As noted, pageviews are a type of hit, but there are also many others including form submissions, click to call, click to get directions, video plays, etc – These actions can be set up as interaction hits or non-interaction hits.
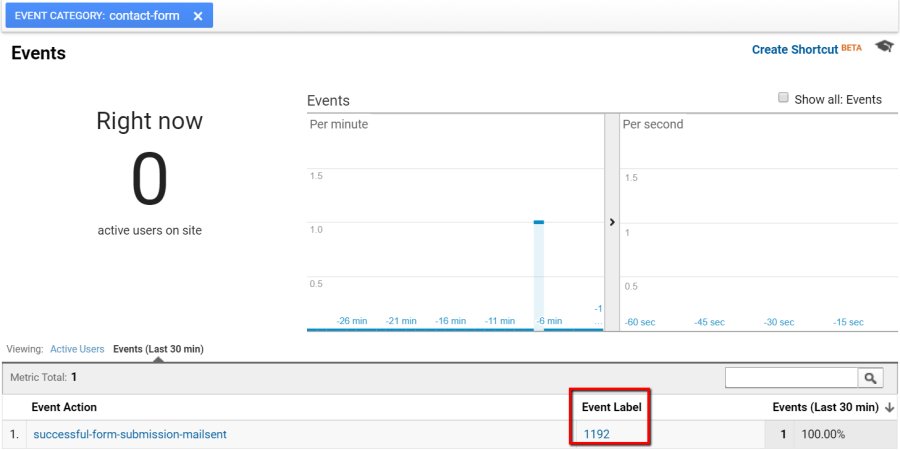
An interaction hit will affect the bounce rate. A person who views one page and fills out a contact form will count as two hits – not a bounce.
A non-interaction hit does not affect the bounce rate. You might want to track video views, but if they’re less of a priority than form fills, you can track them as non-interaction hits. A person who views one page and watches a video that’s configured as a non-interaction hit, will still count as a bounce.
The choice between interaction and non-interaction hits gives you the flexibility to adjust the way bounce rate is calculated, for better data. But that’s not the end of it by any means.
Multi-Touch, Multi-Channel Conversion Funnels
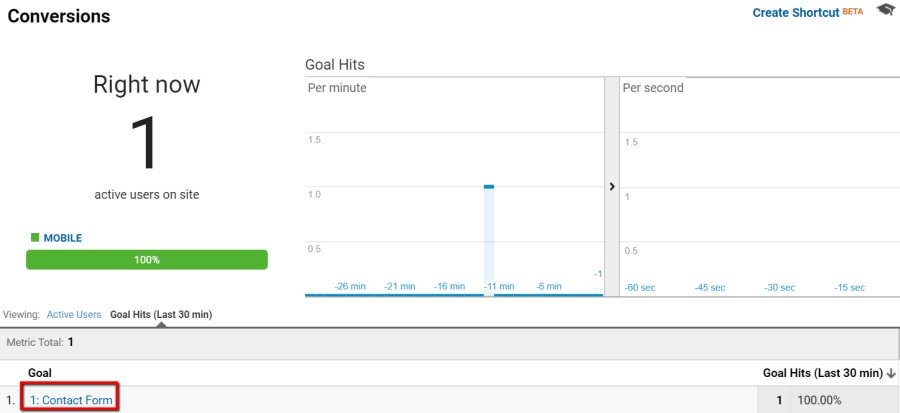
So a single pageview is OK as long as there’s also an interaction hit, but still bad if there isn’t, right? Well…no. That bounce visit could still serve an important role in the customer’s path to conversion. It’s common for marketers to analyze and report on data using Google Analytics’ Last Non-Direct Click attribution model (guilty as charged) and when that happens, it’s easy to over-emphasize bounce rate.
Let me back up again. Google Analytics lets you apply several different attribution models in order to give attribution (credit) to different channels based on their position in the conversion path. You can read more about it here, but the default attribution model is last non-direct click, where the last channel before the conversion receives attribution, unless that channel is direct.
We know a prospective customer may visit a website multiple times before converting. We also know that customer may arrive at the site via a number of different digital channels. The diagram below shows a three touch conversion path (AdWords > SEO > Direct). While the initial touch was an Adwords ad click, organic will get attributed the conversion because it’s the last non-direct touchpoint.

But without careful analysis (and in part due to the last non-direct click attribution model), these three sessions are likely to be viewed from a siloed perspective, without making the connection they all played an important role.

Without looking at the full conversion path, this is going to look great for SEO and not so great for PPC efforts. An SEO-specific report is likely to ignore both the paid search and direct sessions that contributed to the conversion. A report specific to paid search may look at the ad spend as ineffective, since it didn’t convert in that session.
I realize including multiple channels may have you thoroughly confused, so let’s simplify it further and say all three visits were organic. This way there’s no question that organic should be attributed the conversion. Let’s also assign an arbitrary number of pageviews to each visit, as seen below.
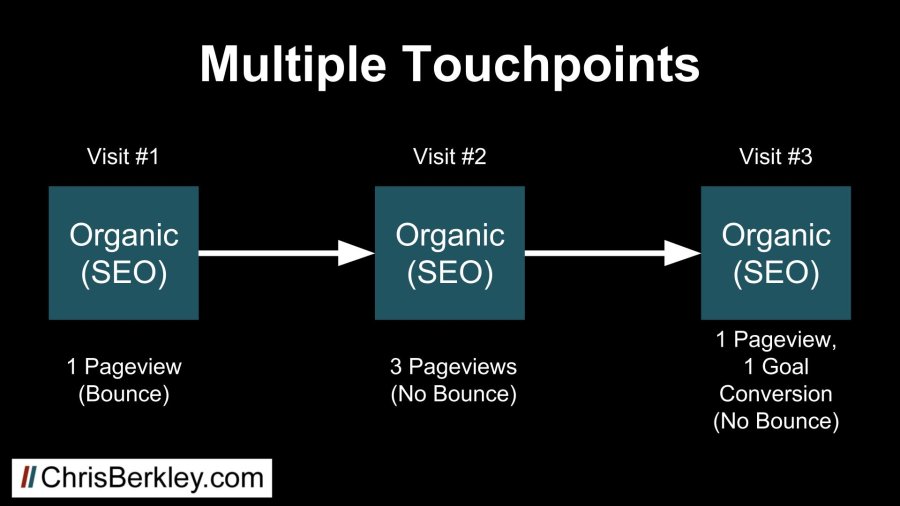
There’s no question about which channel gets the conversion…but it doesn’t change the fact that if analysis is being done at the session-level, these three sessions will not be linked together.
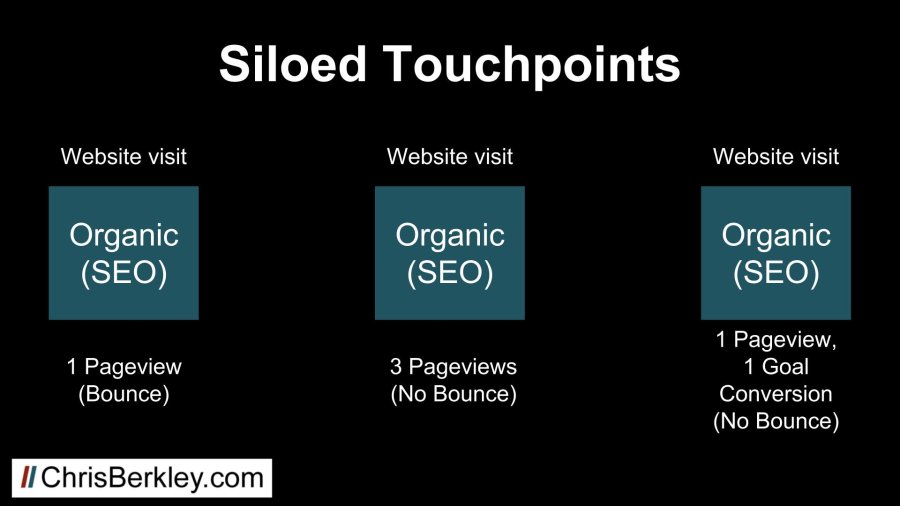
The first visit will be considered a problem because it was a bounce, while the last visit will be celebrated because it resulted in the conversion. Realistically, the last visit may not have happened if it wasn’t preceded by the initial bounce. The middle visit is somewhere in between: not as good as a visit that converts, but at least it’s not a bounce.
It’s possible that all three of these visits played a critical role in the customer journey and discrediting any one of them could result in lost conversions. Similarly, spending time trying to lower bounce rates may be futile if those bounces play a bigger role in a longer path to conversion.
Takeaways
Bounce rate is incredibly complex and boiling it down to good or bad is very, very difficult. As an SEO consultant, I rarely ever focus on bounce rate because I understand this complexity. Bounce rate is not something I report on, and lowering it is never an objective of my campaigns.
SEO projects should be focused on driving relevant traffic that eventually converts into leads, sales and customers, not driving down bounce rates in order to achieve a perceived industry standard or arbitrary metric.
Questions? Comments? Tweet at me (@BerkleyBikes) or drop a comment here!