XML Sitemaps are critical to help search engines crawl websites, but I frequently see clients with critical errors in their XML sitemaps. That’s a problem because search engines may ignore sitemaps if they repeatedly encounter URL errors when crawling them.
What Is An XML Sitemap?
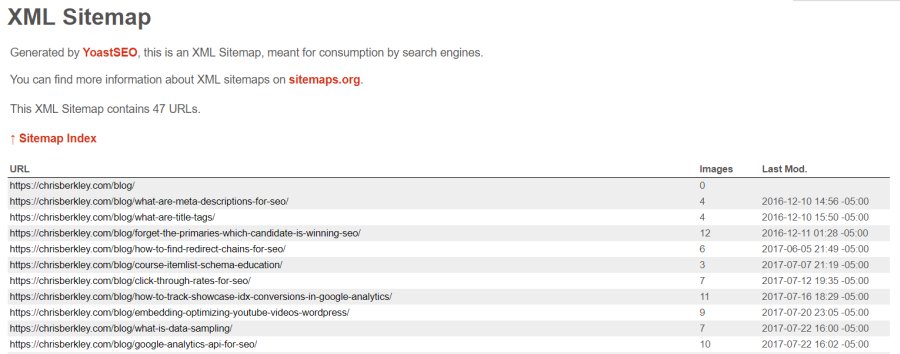
An XML Sitemap is an XML file that contains a structured list of URLs that helps search engines crawl websites. It’s designed explicitly for search engines – not humans – and acts as a supplement. Whereas web crawlers like Googlebot will crawl sites and follow links to find pages, the XML sitemap can act as a safety net to help Googlebot find pages that aren’t easily accessed by crawling a site (typically called island pages, if there are no links built to them).
Where Do XML Sitemaps Live?
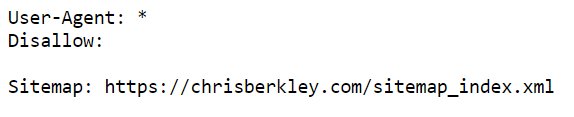
The XML sitemap lives in the root folder, immediately after the domain, and often follows a naming convention such as domain.com/sitemap.xml. A Sitemap declaration should also be placed in the robots.txt file so that Google can easily discover it when it crawls the robots.txt file.
What URLs Should Be Included In An XML Sitemap?
URLs included in the XML sitemap should be URLs that are intended to be crawled, indexed and ranked in search results. URLs should meet the following specific criteria in order to be included:
- Only 200 OK URLs: no 404s, 301s, etc.
- Pages do not contain a noindex tag
- Pages are not canonicalized elsewhere
- Pages are not blocked by robots.txt
HTTP Status Codes
Sitemap URLs should return clean 200 status codes. That means no 301 or 302 redirects, 404 errors, 410 errors or otherwise. Google won’t index pages that return 404 errors, and if Googlebot does encounter a 301 redirect, it will typically follow it and find the destination URL, then index that.
If you have 404 errors, first ask why: was a page’s URL changed? If so, consider redirecting that URL by locating the new URL. Take that new URL and make sure that is included in the sitemap.

If there are 301s or 302s, follow them to the destination URL (which should be a 200) and replace the redirected URL in the sitemap.

Noindexed & Disallowed Pages
If a page has a noindex tag, then it’s clearly not intended to be indexed, so it’s a moot point to include it in the XML sitemap. Similarly, if a page is blocked from being crawled with robots.txt, those URLs should not be included either.
If you DO have noindexed or disallowed pages in your XML sitemap, re-evaluate whether they should be blocked. It may be that you have a rogue robots.txt rule or noindex tags that should be removed.]
Non-Canonical URLs
If a page in the sitemap has a canonical tag that points to another page, then remove that URL and replace it with the canonicalized one.
Does Every Clean 200 Status URL Need To Be Included?
In short, no. Especially on very large sites, it may make sense to prioritize the most important pages and include those in the XML Sitemap. Lower priority, less important pages may be omitted. Just because a page is not included in the XML sitemap does not mean it won’t get crawled and indexed.
Sitemap Limits & Index Files
An XML sitemap can only contain 50,000 URLs or reach a file size of 10MB. Sitemaps that exceed this limit may get partially crawled or ignored completely. If a site has more than 50,000 URLs, you’ll need to create multiple sitemaps.
These additional sitemaps may be located using a sitemap index file. It’s basically a sitemap that has other sitemaps linked inside it. Instead of including multiple sitemaps in the robots.txt file, only the index file needs to be included.
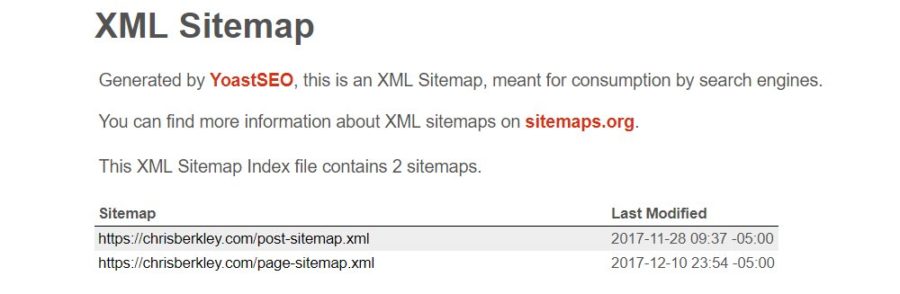
If there ARE too many URLs to fit into one sitemap, URLs should be carefully and methodically structured in hierarchical sitemaps. In other words, group site sections or subfolders in the same sitemap so that Google can get a better understanding of how URLs interrelate. Is this required? No, but it makes sense to be strategic.
Types of XML Sitemaps
In addition to creating sitemaps for pages, sitemaps can (and should) be created for other media types including images, videos, etc.
Dynamic vs. Static
Depending on the CMS and how it’s configured, the sitemap may be dynamic, meaning it will automatically update to include new URLs. If it’s configured correctly, it will exclude all the aforementioned URLs that shouldn’t be included. Unfortunately, dynamic sitemaps do not always operate that way.
The alternative is a static sitemap, which can easily be created using the Screaming Frog SEO spider. Static sitemaps offer greater control over what URLs are included, but do not automatically update to include new URLs. In some cases I’ve recommended clients utilize static sitemaps if a dynamic sitemap cannot be configured to meet sitemap criteria. When that happens, I set a reminder to provide an updated sitemap, typically on a quarterly basis, or more often if new pages are frequently added to the site.
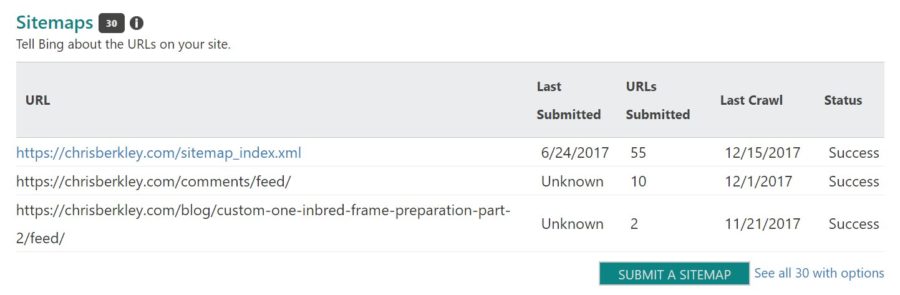
Submission to Webmaster Tools
Once an XML sitemap has been created and uploaded, it should always be submitted to Google Search Console and Bing Webmaster Tools to ensure crawlers can access it (in addition to the robots.txt declaration).
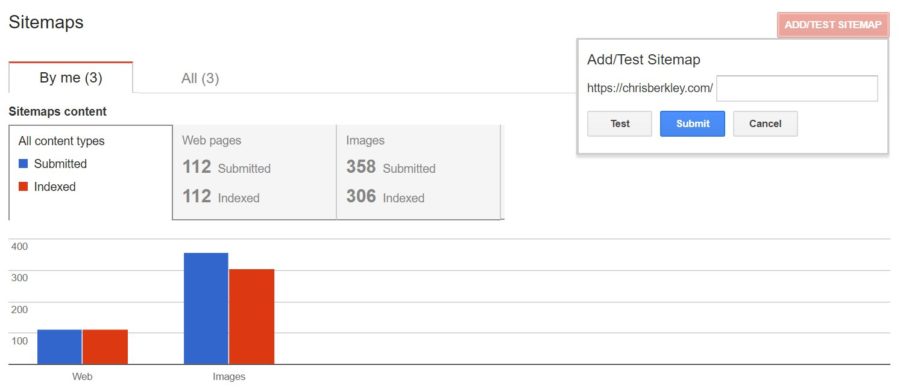
In Google Search Console
Navigate to Crawl > Sitemaps and at the top right you’ll see an option to Add/Test Sitemap. Click that and you can submit your sitemap’s URL to be crawled.
In Bing Webmaster Tools
From the main dashboard, navigate down to the sitemaps section and click “Submit a Sitemap” at the bottom right. There you can enter your sitemap’s URL.