Time and time again, Google has shown that they treat subdomains very differently from root domains, in some cases treating them as completely different sites. For SEO purposes, it’s generally recommended to use a subfolder instead of a subdomain.
Subdomain vs. Subfolder
A subdomain is a string of characters that precedes the root domain and uses a period to separate them. A subfolder comes after the domain suffix and is separated by a forward slash. You can have multiple subdomains or subfolders, and you’ll frequently see them combined.
Examples:
- Blog.chrisberkley.com is a subdomain
- Chrisberkley.com/posts/ is a subfolder
- Blog.chrisberkley.com/posts/ is a subdomain with a subfolder.
- First.blog.chrisberkley.com is two subdomains (“first” and “blog”)
- First.blog.chrisberkley.com/posts/recent/ is two subdomains (“first” and “blog”) with two subfolders (“posts” and “recent”).
Did You Know?
In the URL www.chrisberkley.com, “www” is technically a subdomain. It’s true!
Why Use Subdomains?
There are legitimate reasons that necessitate the use of subdomains and subdomains are not completely unavoidable.
Technical Limitations
Sometimes there are technical infrastructure limitations that prevent the use of a subdomain. In large organizations with big sites, it’s common for access to the root domain to be limited, instead using subdomains for ease of use.
This may include piecing together multiple CMSs. If the core site is hosted on one CMS like Magento or Sitecore, but the blog is hosted on WordPress, it can be difficult (or impossible) to make them work together on the root domain.
Organizational Control
Large organizations often have multiple divisions that operate independently. Such is the case with universities, where individual colleges need to have edit access to their own sites (School of Nursing, School of Engineering, etc.). The same is true for other national organizations like banking institutions.
It’s a lot easier to spool up a separate site on a subdomain and grant a team of people edit access to that particular subdomain. You wouldn’t want the School of Nursing making edits that ended up taking down the entire root domain for the whole college.
International
Sometimes organizations will create international subdomains like fr.chrisberkley.com or en.chrisberkley.com. There’s no inherent SEO benefit to including a country code in the subdomain, but it may comeback to organizational structure or technical limitations. In a perfect world, you’d place those in subfolders (chrisberkley.com/fr/ or chrisberkley.com/en/) and implement hreflang. Alas, we don’t live in a vacuum and that isn’t always possible.
How Google Treats Subdomains
Working with subdomain-heavy clients, my firsthand experience is that Google treats subdomains as separate sites. A client of mine who had two divisions of their company had one set up on subdomain and another on the root domain. They had some content overlap and we sometimes saw their pages swap places in search results.
It’s my belief that subdomains don’t inherit domain authority or site equity from the root domain. WordPress.com has a domain authority of 94. If subdomains inherited that value, wouldn’t it make sense to setup free blogs on their platform (which uses subdomains) and immediately benefit from the SEO value?
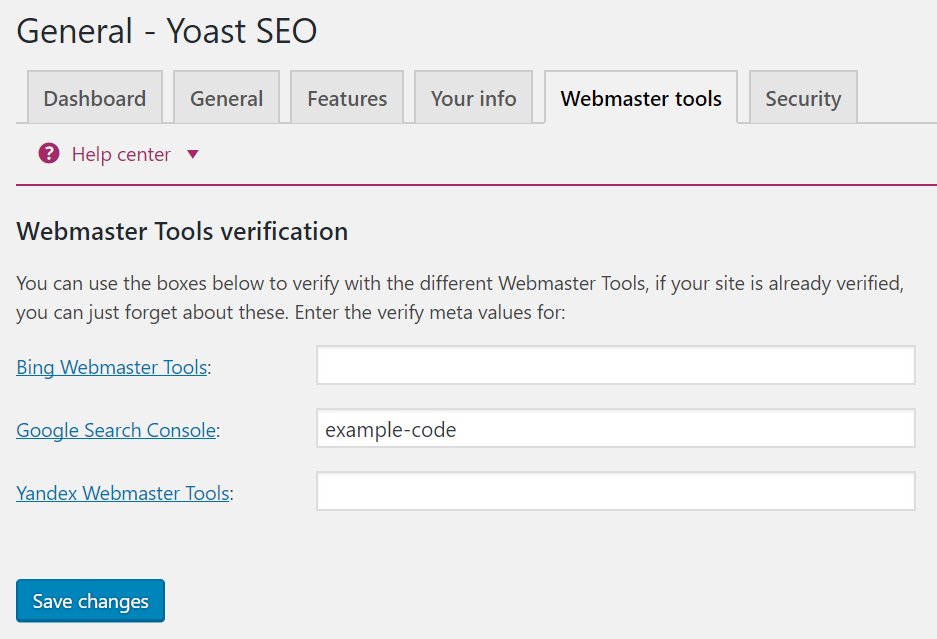
Secondly, Google’s own Search Console requires you to set up separate profiles for subdomains. That’s another good indicator that they value subdomains differently.
That doesn’t mean subdomains inherit ZERO equity from their root domains. They may inherit a greatly reduced amount. OR, Google may adjust the amount of equity they inherit on a case-by-case basis. Since WordPress.com has thousands of low-authority blogs on subdomains, Google may devalue their subdomains more than other sites that only have a handful.
Google has stated that their search engine is indifferent to subdomains vs. subfolders, but the SEO community has repeatedly found that to be false. Industry thought-leader Moz moved their content from a subdomain to a subfolder and saw measurable increases just as a result of that move.
I think @randfish will like a graph like this ⬇️. Results of moving a blog from subdomain to subfolder… pic.twitter.com/ACQOVpY0H0
— Gianluca Fiorelli (@gfiorelli1) March 10, 2017
Questions? Comments? Leave them here or reach out to me on Twitter: @BerkleyBikes.