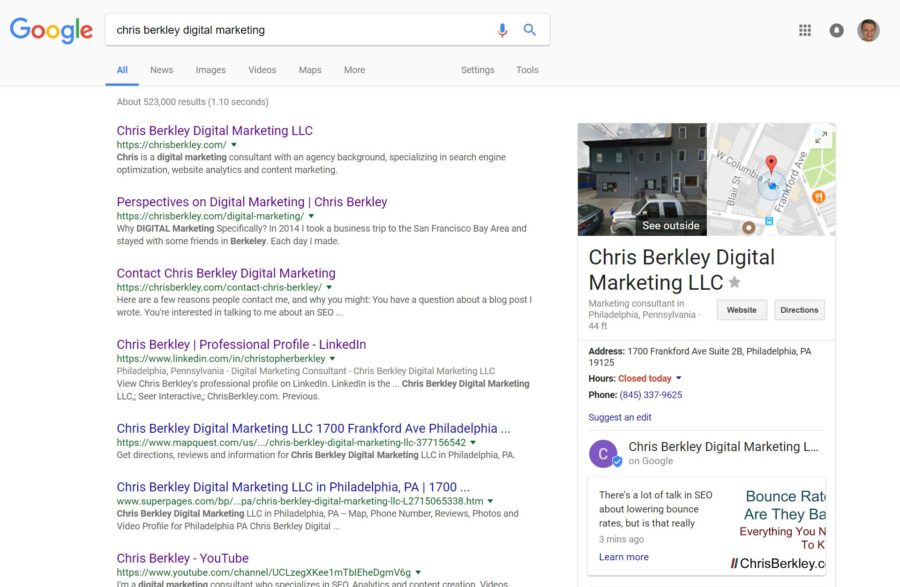
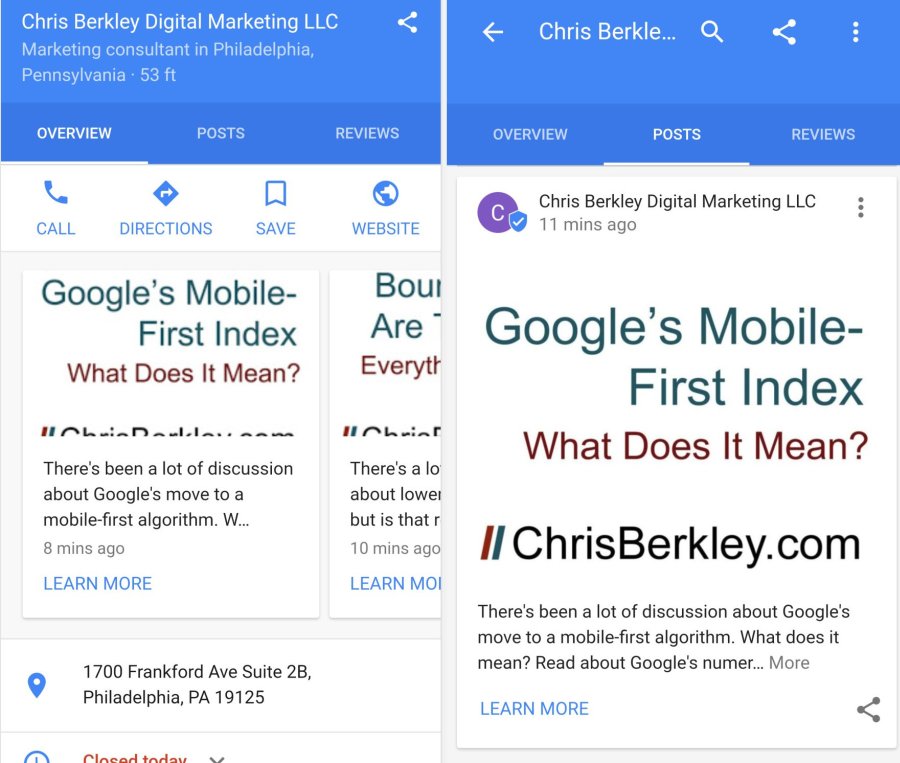
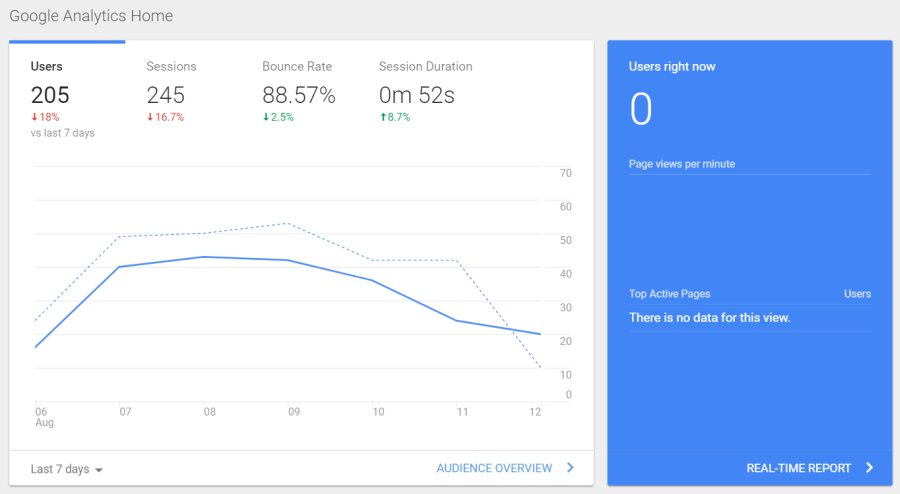
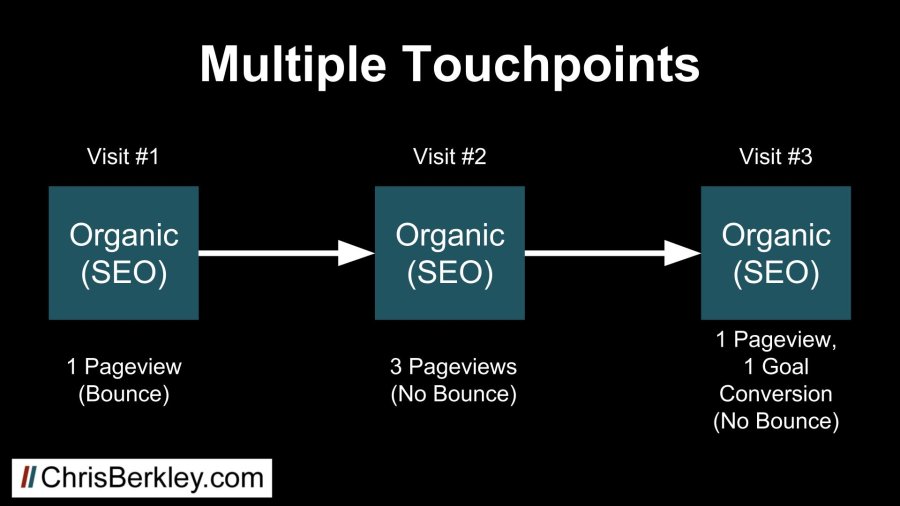
WordPress is a brilliant CMS that offers a plethora of SEO functionality out-of-the-box. But like any piece of technology, default settings won’t be enough to truly maximize its potential.This post will show you how to optimize a WordPress post (or page) for SEO purposes.
The WordPress SEO Plugins
While WordPress is good out of the box, it needs an SEO plugin to take it to the next level. The gold standards are either Joost de Valk’s Yoast SEO Plugin or All In One SEO Pack by Michael Torbert. Both add critical functionality for SEO purposes, so make sure you have one installed.
Content
No amount of optimization will help if you’re targeting topics with low or non-existent search volume. The same can be said for high volume (and high competition) topics. You have to pick topics and themes that are realistic and within your wheelhouse to achieve SEO success.
First we’ll start with the post content itself, focusing on how to structure the page with H headings and overall content length.
H Headings & Page Structure
Start by adding a post title. In many WordPress themes, the post title will also be present on the page as an H1 heading. Pages should only have one H1 heading and it needs to be keyword-rich and descriptive of the post’s content. The H1 is the first text a visitor sees when they hit the page.

In addition to H1 headings, it’s increasingly important to structure pages with additional, nested H headings like H2s, H3s, H4s, etc. These should also be keyword-rich and describe the subsequent paragraph. On this very page you’ll see a clear structure where paragraphs are ordered and grouped by similarity and marked up with a clear hierarchy of H headings.
If you know your subject matter and audience well, developing a hierarchy of H headings may be second nature to you. If not, performing keyword research can typically reveal different subtopics and then you can apply common sense to order them in the method that makes the most sense for visitors.
Ordered and Unordered Lists (Bullet Points)
To break up content and make it more digestible, use ordered lists (numbered lists) and unordered lists (bullet points) where applicable. Using these with a keyword-rich H heading may result in securing a featured snippet (answer box) in search results.
- Anytime you’re describing steps, consider using an ordered list.
- If you’re listing several things using commas, try bullet points instead.
This is not only helpful for SEO, it helps readers digest a page more easily.
Content Length
Content length is much debated and the honest answer to “what’s the right length” is that there isn’t one. If the content is engaging, people will read it. Know your audience, write quality content and you’ll succeed.
With that being said, 250-300 words is commonly considered the absolute minimum for SEO purposes. Less than that and search engines may deem the content thin. It will be incredibly difficult to add a meaningful structure of H headings to a page with 300 words.
I recommend content that’s a minimum of 500-700 words. In many cases, long form content can do wonders for SEO and when I say long form I mean 1,000 words or more. Most of my successful posts are detailed how-tos in excess of 1,000 words. Your mileage may vary – put your focus on writing good content and worry less about the length.
Video, Images & Media
Video, images and media are also great ways to break up text-based content and provide additional value for visitors. Would the topic you’re discussing be more easily understood if a visual were added? In many cases, yes.
Here I’ll discuss ways to optimize media for SEO, and also for visitors with disabilities or impairments, who may not be able to consume images, video or audio.
Image Optimization
Images can be improved for SEO by using filenames, alt text and by optimizing image sizes (for site speed). Because search engines can’t visually determine the contents of an image, these optimizations allow them to understand image content, helping the page rank better and helping images to rank in image search results. Additionally, visitors with visual impairments may not be able to see images, so these optimizations help them consume and understand multimedia content.
Image Filenames
Including keywords in filenames can have impact. It’s not huge, but every bit helps. Use descriptive keywords in filenames when possible but don’t start keyword stuffing – make them descriptive and methodical.
Image Alt Text
Include image alt text when possible. The alt text is never seen by visitors unless A) the image doesn’t load or B) the visitor is impaired and the alt text is read to them.
Both of these scenarios help visitors understand the content of the image, even if it can’t be seen. For that reason, make your image alt text descriptive of what’s in the image and avoid keyword stuffing.
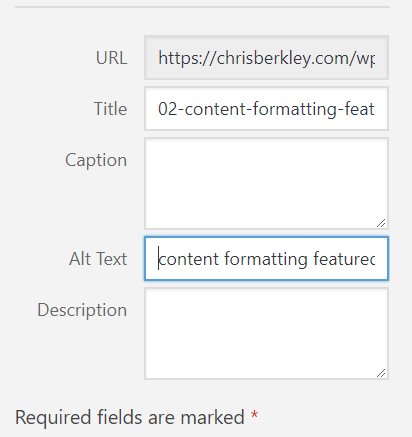
The alt text for the image immediately above: wordpress seo image alt text
Image Size Optimization
Your images should only be as large as they need to be. Often, GIANT images are scaled down to a much smaller size with HTML. The problem is, if you have a giant image with an enormous file size, browsers have to load the entire image, even if it’s being displayed at a much smaller size. That slows down page speed, especially if there are multiple large images on the page.
Make the image as big as it needs to be. If the image will be displayed at 900 pixels wide, then make it 900 pixels wide. Secondly, use JPG images instead of PNGs – JPGs are significantly smaller in file size. If you don’t have an image editing program, you can do it right in WordPress from the Media Library menu.
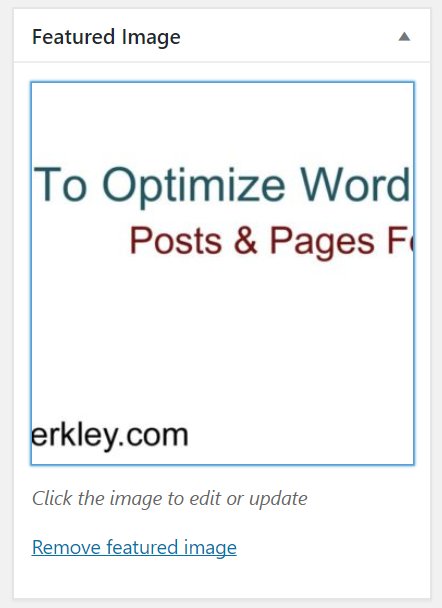
Featured Images
Add a featured image. The featured image will be used as the default image when a page or post is shared on social media, although this can be changed for different social networks.
Video
Similar to images, video content also has opportunities for on-page optimization. Video content is equally hard for search engines to understand, so we optimize by adding context in other ways.
Embedding
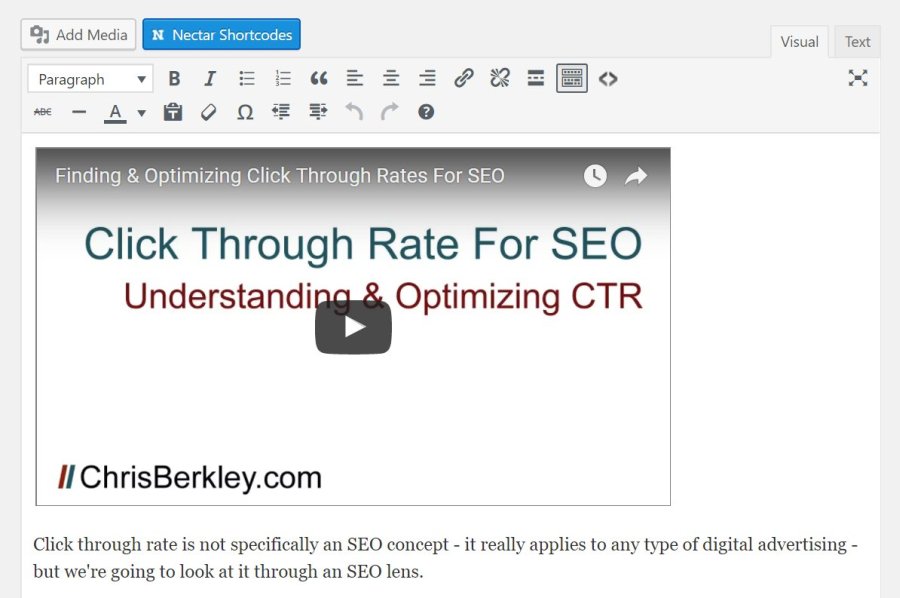
Embedding video content on WordPress posts or pages is quite easy, especially for YouTube, Wistia and Vimeo. With any of these three, you can simply drop the URL into WordPress’ WYSIWYG editor and it will automatically embed the video. Embedding videos on-site is a great way to get more views and provide a superior user experience.
Schema
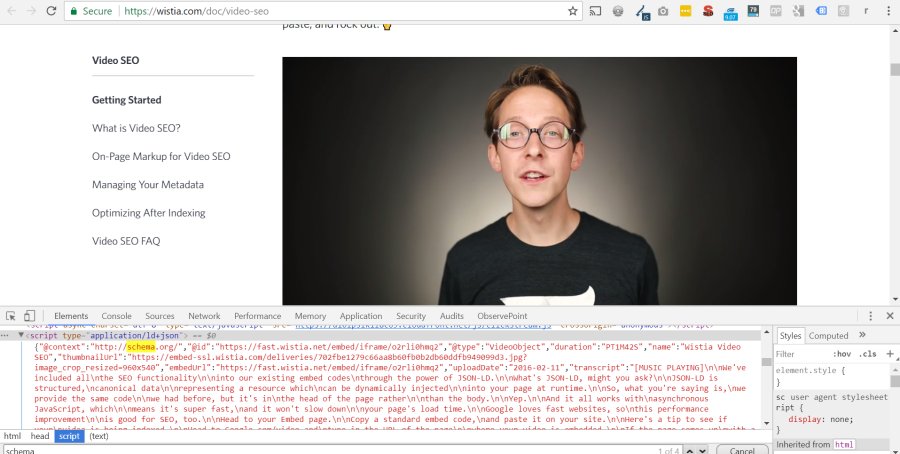
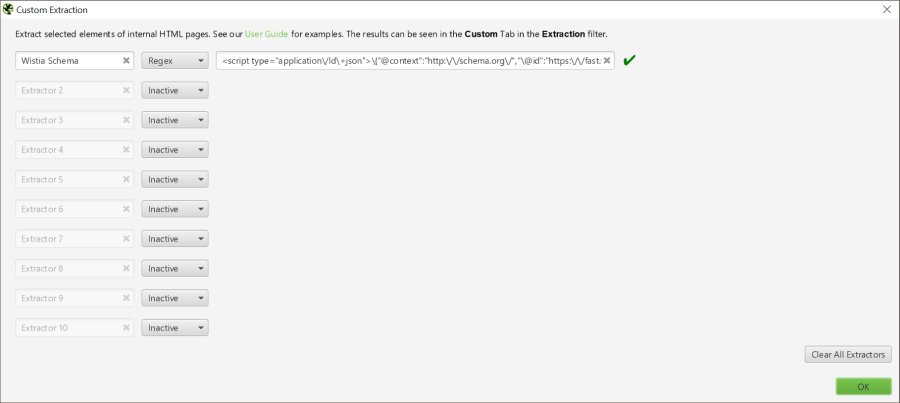
When you do embed video content, make sure you add Schema as well. If you’re using Wistia, you’re in luck, because Wistia embeds Video Schema by default using Javascript (read more about Wistia videos & schema here).
YouTube and Vimeo users are not as fortunate however, and must add Schema manually, preferably using custom fields. JSON is Google’s preferred version of Schema and creating the Schema is not difficult at all. Schema gives search engines additional information about videos, such as the video’s title, description, length, upload date, etc. Schema is the only way for search engines to get information about video contents.
<script type="application/ld+json">
{
"@context": "http://schema.org",
"@type": "VideoObject",
"name": "Contact Form 7 Goal Conversion Tracking Google Tag Manager",
"description": "Follow this 10 minute guide to set up Google Analytics goal conversion tracking for Contact Form 7 submissions using Google Tag Manager.
If you have a WordPress website and you use the Contact Form 7 plugin, you can use Google Tag Manager to create events and set up Goal Conversions in Google Analytics. Then you can attribute form submissions to different marketing channels and campaigns that you're running.
This guide not only shows you how to track submissions, but also ensures that you're only tracking successful submissions where mail is actually sent. It also allows you to specify which forms you want to track, based on the form ID built into the Contact Form 7 shortcode.
***Links***
Written how-to guide: https://chrisberkley.com/blog/contact-form-7-event-tracking-google-tag-manager/
Javascript code for Tag #1:
https://chrisberkley.com/wp-content/uploads/2017/11/wpcf7mailsent-javascript.txt
Troubleshooting your setup:
https://chrisberkley.com/blog/troubleshooting-contact-form-tracking-with-gtm/",
"thumbnailUrl": "https://i.ytimg.com/vi/oTZG7A3RjT8/maxresdefault.jpg",
"uploadDate": "2017-11-19",
"duration": "PT10M1S",
"embedUrl": "https://www.youtube.com/embed/oTZG7A3RjT8"
}
</script>
Transcripts
Transcripts can be really critical. Not only do they give impaired users a full transcript of the video’s content, but they can be keyword-rich and help a page rank if the video is especially relevant to the target keywords.
I don’t always include transcripts, but often recommend including them in an accordion drop-down, so as not to disrupt the flow of existing text on the page. If the page doesn’t have much additional text, transcripts can easily be adapted into blog posts.
Meta Data
Meta data is still really important for SEO. Both Yoast’s plugin and All In One SEO make it very easy to add a title tag and meta description, even warning you if you approach character limits.

Title Tags
Using your chosen SEO plugin, write and add an optimized title tag. Shoot for 45-60 characters. Excessively long titles will be truncated in search results.
I prefer to include the target keyword at the beginning and then include branding at the end. Title tags should grab the searcher. I’m a fan of using question-based title tags if they’re relevant. Here’s the title tag for this post:
How To Optimize WordPress Posts & Pages For SEO | Chris Berkley
Meta Descriptions
Meta descriptions should be up to 230 characters and describe the page’s contents – be as descriptive as possible. Meta descriptions are the key to encouraging searchers to click through from search results and can have a big impact on click through rates.
Tell searchers what value the page will provide and what they’ll find. Include branding if possible. End with a CTA telling them what to do once they land on the page.
Here’s the meta description for this page:
Optimizing WordPress posts and pages is critical for SEO. Follow this comprehensive guide to make sure your content is FULLY optimized, using all of WordPress’ advanced functionality.
Social Markup
SEO plugins make it easy to add Open Graph and Twitter Card markup to the page. These meta tags are specifically for social media and add rich snippets when URLs are included in social posts.
Even without social markup, most social networks will pull the page title, description and image to create a rich snippet. However, these aren’t always optimal – they frequently pull the wrong or completely irrelevant images. Optimizing this markup allows you to customize titles, descriptions and images for use on social media.
Open Graph Markup
Open Graph is a standard markup most notably used by Facebook, LinkedIn and Pinterest. The two SEO plugins I mentioned before automate the creation of Open Graph markup using the title tag, meta description and featured image that you’ve added to the page. However, they also allow you to customize these fields specifically for social media – this is especially easy using the Yoast plugin.
Say you wanted to add a catchier title/description/image for use on social media. You can do that without impacting your SEO efforts by changing the title tag & meta description that Google uses.

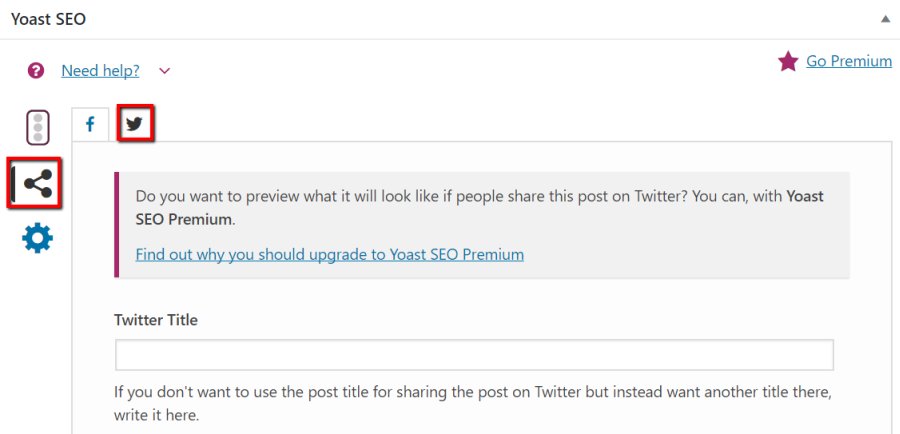
Twitter Cards
Rather than use Open Graph markup like most other networks, Twitter elected to create its own (very similar) markup called Twitter Cards. You can customize these too just like Open Graph markup.
Linking
Internally linking pages is really important for both visitors (they can find related content) and search engines (can crawl the site more easily). Internal links can be added in a number of ways, but some are more valuable than others.
Links In The Body Copy
Body copy links are arguably the most valuable, assuming they’re done naturally and in moderation. No one likes a page where every other sentence is a link – it’s incredibly distracting and results in a poor user experience. Use links where they fit naturally.
Internal Links
Internal links (links from one page on your site to another page on your site) are valuable for helping visitors find related content and improving the ability for search engines to crawl the site. I recommend setting these to open in the current tab.


External Links
Linking out to other sites is fine too. If there’s a page on another site that would provide value to your visitors, link out to it. I recommend opening these in new tabs, to encourage visitors to stay longer on your site.

Anchor Text
Anchor text is the phrase that gets hyperlinked to another page. You should aim to use keyword-optimized anchor text, especially for internal links (keyword-rich anchor text is not as necessary for external links).
There are several links within this article that link out to other related topics, using anchor text keywords relevant to those topics.
Categories & Tags
Use Categories and Tags methodically. Keyword stuffing them has no benefit for SEO purposes. Instead, they should be used to help visitors browse the site to discover related content. Additionally, Categories & Tags have a ton of value for search engines as they make it easy to crawl the site and find additional pages.
Categories & Tags are the first line of defense against island pages and semi-automate internal linking. However, blog category pages typically contain dynamic content (unless setup otherwise) and typically don’t present much value for ranking purposes.
Build out some pre-determined Categories & Tags and stick to them, adding new ones as you go. Avoid using the same categories as tags and vice versa. Think of Tags as sub-categories. Below is a sample diagram of a Category-Tag structure.

Authors
Adding author details can establish credibility to the post by showing an appeal to authority. WordPress editors have the option of changing the author at the bottom of the post. Don’t ever leave the post author as “Admin.”

Authors should have photos & biographies describing who they are. There’s no inherent SEO value here (not anymore), but it shows readers who actually wrote the content. I always include links to my Twitter page for people to ask questions about my content.

Technical
Schema
Schema (Structured Data) helps search engines crawl and index web pages by specifying specific pieces of content. There are many types (I won’t describe them all) which can be found at Schema.org.
A few common types are:
- Video
- Product
- Person
- Location
I recommend following Torquemag’s guide to setting up custom WordPress fields for Schema. You can also read more about Schema and Structured Data with Google’s developer documentation.
URL Structure
When you save your post or page as a draft, you’ll see that WordPress automatically takes the post title (H1) and also uses it for the URL. In this case, you may choose to edit the URL, but make sure it’s still keyword-rich. You want your most valuable keywords in the URL.

If you’re creating a page (not a post) you’ll see that you have the option of selecting a parent page. Should you add one? It comes down to site structure and strategy. If the page you’re creating falls naturally as a child page to another page, then take advantage of it.
Adding a child/parent page isn’t a silver bullet for SEO. It’s part of a bigger SEO strategy centering around how content is structured on your site. If have a careful hierarchy built out, adding URLs that reflect the site structure is icing on the cake.

The Difference
Following these steps can be the difference between content that ranks and content that doesn’t. Content has been increasingly important, especially as backlinks have become less influential as a ranking factor.
Checklist
If the number of steps seems intimidating, download this checklist and integrate these steps into your content publishing process.
Download The Checklist